NetBeans 8.2 is out, multiple cursors and all, so it’s a fitting occasion to post my five favorite features. First, some background to avoid making a just-downloaded-an-went-a-bloggin’ impression: I’ve been working daily with NetBeans since version 6 (so this post has been brewing for a while). I mostly work with Java (core, Java EE and some Swing) and with HTML/Javascript. I’ve also used NetBeans for Markdown, Scala, PlantUml, Sphinx, Python, Ruby, and making coffee. OK, forget the Ruby part.
When joining the data science team at the Institute of Quantitative Social Science at Harvard, I was happy to see they were using NetBeans as well. Dataverse, our institutional data repository system, is based on Java EE and is developed with NetBeans. It’s currently more than 97K lines of open-source code*. So you can see I have some milage using this tool.
BTW, I’ve worked with the common alternatives (both paid and free) but somehow I always come back to NetBeans. I guess I just don’t like my code being eclipsed.
OK, OK, no need to throw a BadPunException. Let’s get to it:
Little Comforts/Going the Extra Mile
Such as the suggested variable names, auto-pasting traces to the stack trace analyzer, the fact that the stack trace analyzer exists, “view differences” in the Unit testing result pane, get + code-completion generates the proper getter (there’s also a setter, of course).
And then there are the top-of-block popup and the file-too-long label. Love these.
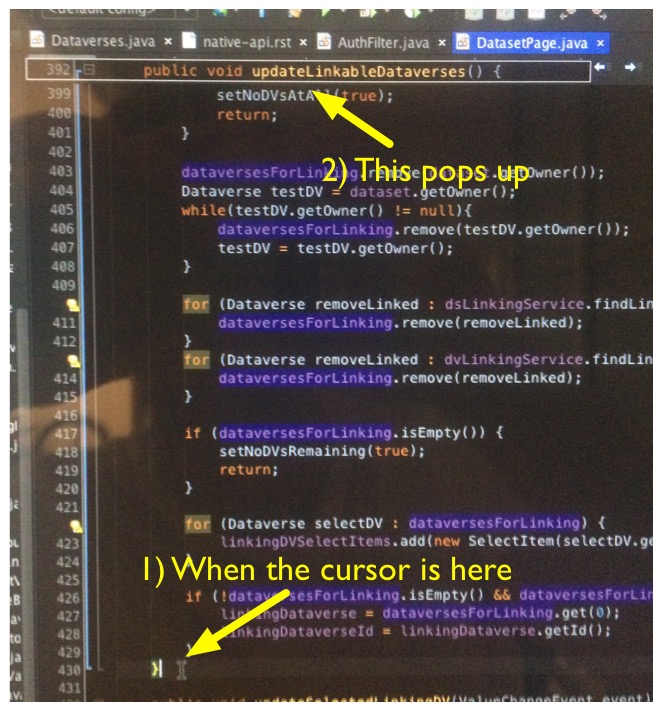
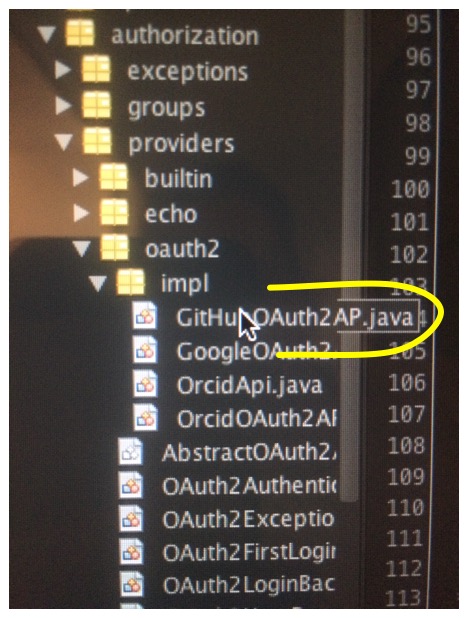
Additionally, NetBeans includes the required stuff out of the proverbial box. JUnit, Git etc. No need to install manually and decide between various conflicting versions of third party plugins.
Project Groups
Switch quickly between groups of projects. Or, really, working contexts. Since I have a few separate contexts I’m working on in parallel, this feature is a huge timesaver.
Great Java (+EE) and Javascript Support
Great language support for Java (including the next version). Very good Javascript support as well. The code warnings are useful, and the “convert to functional operation” refactoring had taught me some new Java 8 features I was not aware of.
Good support for Java EE features, such as integration and plugins (JPQ modeler etc.). Integration with application servers etc. is easy. There’s also Docker integration, I hear. I’m not using Docker currently. I hope I can still keep my developer license.
Not reinventing the wheel
For example, using Apace ant at the core of the native project type make these projects useful outside of NetBeans too (an anti-vendor-lock-in vendor!).
It Just Works
It does. Srsly. It’s a very dependable tool. And I’m looking forward to seeing it graduating from its Apache incubator.
* Count generated using David A. Wheeler’s ‘SLOCCount’.